Article
Loop Engineering 的本质:让 Agent 一轮一轮走向交付
最近我越来越觉得,Agent 工程化会从“怎么让模型更会回答”,慢慢走到另一个问题:
怎么让模型在一个长任务里,一轮一轮把事情做成。
这就是我理解的 Loop Engineering。
它的本质不是让 Agent 一直跑。
而是让 Agent 每跑一轮都离目标更近,并且知道什么时候该停。
很多人看到 Loop Engineering,第一反应会觉得:这不就是 while true 吗?
不是。
while true 只是循环。Loop Engineering 要解决的是闭环。
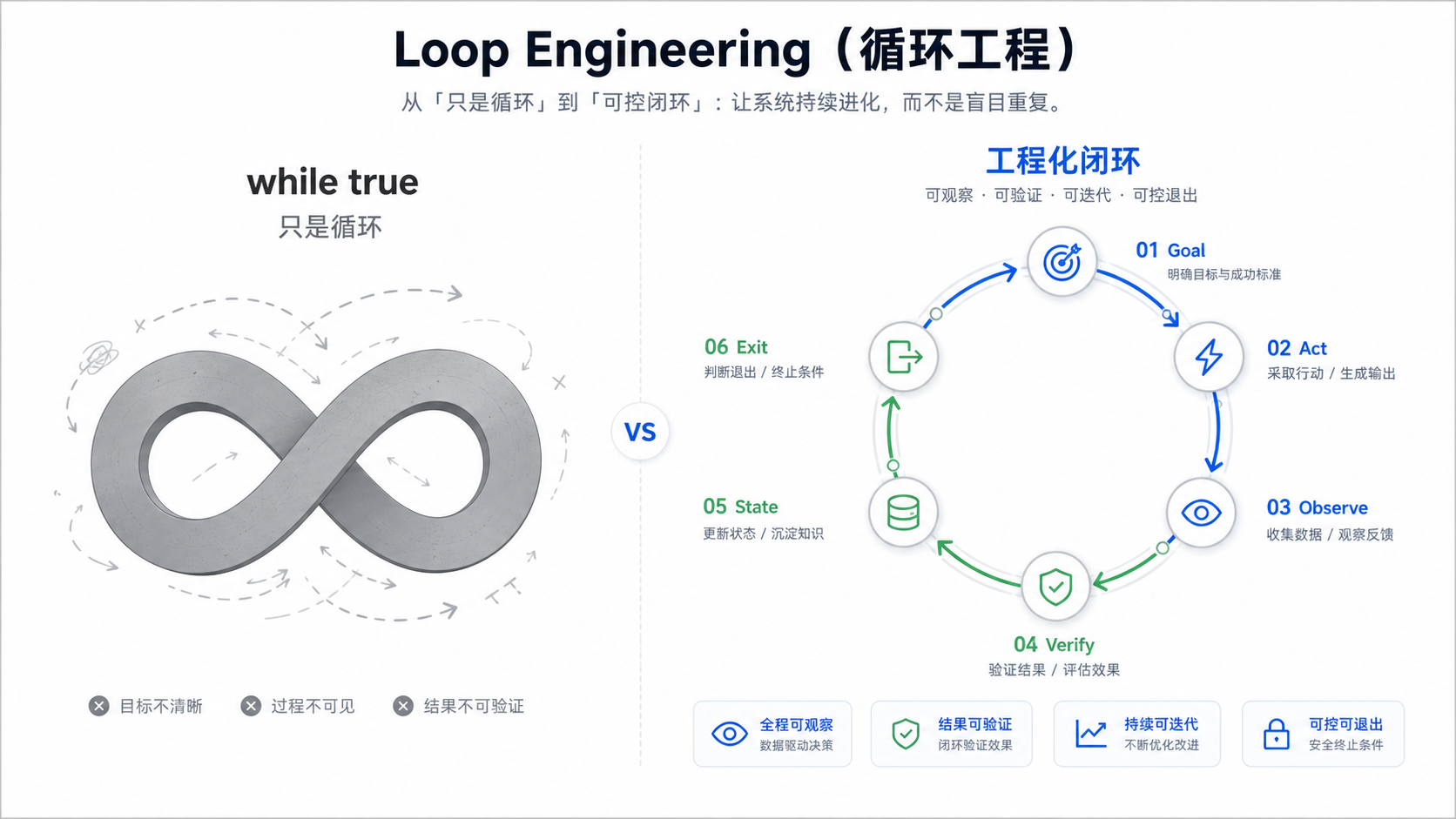
循环只是重复,闭环要有目标、观察、验证、状态和退出条件。
长任务里,问题不再是第一轮回答
我最近有个很直观的体感。
我有一个 Codex 的 goal 任务,已经运行了 1d 19h 48m,还在继续跑。
不是开个聊天窗口问两句,也不是让模型生成一段代码就结束,而是一个持续目标。它要不断读取上下文、判断进展、执行动作、验证结果,遇到问题继续调整。
长任务里,真正重要的不是“它还在跑”,而是它为什么继续跑。
这个场景里,真正让我关心的已经不是“这一轮 prompt 写得好不好”。
我关心的是:
- 它现在到底在做什么?
- 它为什么认为下一步该这么做?
- 它做过哪些尝试?
- 哪些失败已经被排除?
- 现在离目标还有多远?
- 什么时候应该继续,什么时候应该停?
- 如果我中途回来接手,能不能看懂它留下的状态?
这就是 Loop Engineering 开始变重要的地方。
过去我们怎么用 AI?
其实是人在手动跑 loop。
你问一句,它答一句。你发现不对,再补充一句。它写了代码,你复制去跑。报错了,你把报错贴回去。它再修一版。你再看 diff,再跑测试。
整个循环是:
人提出目标 -> AI 生成 -> 人观察结果 -> 人反馈 -> AI 再生成
这里真正负责控制循环的人,是你。
AI 只是循环里的一个生成器。
但 Agent 不一样。
Agent 一旦开始读文件、改代码、跑命令、调用工具、写 PR、等待测试结果,它就不再只是“回答者”,而是在执行一个持续任务。
这时候如果还只靠 prompt,就会很脆。
因为长任务里最难的不是第一轮回答,而是第十轮、第二十轮、失败之后的下一轮。
Loop Engineering 工程化的是“下一步”
我理解的 Loop Engineering,核心不是循环本身,而是工程化这几个问题:
- 下一步做什么?
- 根据什么判断下一步?
- 上一步结果怎么进入上下文?
- 失败以后是重试、换策略,还是交还给人?
- 什么证据算完成?
- 成本、权限、风险怎么限制?
- 什么时候停止?
你看,里面没有一个问题是“写一句神奇 prompt”能解决的。
Prompt Engineering 关注的是这一轮怎么问。
Context Engineering 关注的是这一轮该给模型看什么。
Harness Engineering 关注的是模型在真实环境里怎么安全执行。
Loop Engineering 关注的是:多轮之间怎么推进。
它把 prompt、context、tool、memory、verification、policy 串成一个持续运转的系统。
一个靠谱的 Coding Agent loop,通常不是“生成代码 -> 再生成代码 -> 再生成代码”。
它更像这样:
先根据目标拆计划。然后读相关文件。再做最小修改。跑测试。测试失败就分析失败原因。如果是自己改坏了,就回到修改环节。如果是环境问题,就标记阻塞。如果测试通过,还要看 diff 有没有越界。最后生成证据:改了什么、验证了什么、还有什么风险。
这才是闭环。
只有“生成代码 -> 再生成代码 -> 再生成代码”,那不叫 Loop Engineering,那叫自动堆垃圾。
好的 Loop,不是跑得久
很多人会误解这一点。
以为 Agent 能连续跑 10 小时、20 小时,就是 Loop Engineering 做得好。
其实不一定。
一个没有退出条件、没有验证器、没有状态压缩、没有成本控制的长循环,可能只是 token 黑洞。
真正好的 Loop,不是“它一直在跑”。
而是它每一轮都能回答:
我为什么继续?
我继续之后要验证什么?
验证失败以后我怎么改?
到什么程度我应该停下来?
我现在会把一个 Agent Loop 拆成几层。
Goal:目标是什么。目标不能只是“帮我做一下”,而要能被推进、被验证。
Planner:下一步怎么选。不是一开始幻想完整路径,而是根据当前状态滚动规划。
Actor:真正执行动作。读文件、改代码、调 API、跑命令、查资料,都在这里。
Observer:观察结果。工具输出、测试结果、日志、diff、错误信息,都要回到系统里。
Verifier:判断有没有变好。这一层非常关键。没有 verifier 的 loop,很容易自嗨。
State:记录状态。做过什么、失败过什么、现在卡在哪里、下一步为什么这么选,都要留下来。
Exit Condition:退出条件。成功退出、失败退出、预算退出、风险退出、人类接管,都要定义清楚。
Policy:策略约束。权限、成本、模型路由、重试次数、敏感操作审批,都属于这里。
这些东西组合起来,才是一个真正能跑长任务的 loop。
为什么现在开始讲 Loop Engineering
因为 Agent 开始进入长任务了。
以前大家主要聊 Prompt Engineering,是因为模型只能回答一轮。
后来开始聊 Context Engineering,是因为模型能处理更长上下文,大家发现“给它看什么”比“怎么问它”更重要。
再后来开始聊 Harness Engineering,是因为 Agent 开始动真实系统,必须有沙箱、权限、审计、回滚和验证。
现在 Loop Engineering 被拿出来讲,是因为 Agent 开始从“单次执行”走向“持续执行”。
Coding Agent 是最明显的例子。
写代码不是一句话的事。
它要理解需求、读代码、定位文件、修改、跑测试、修复失败、再验证、再总结。复杂一点的任务还会跨多个 repo、多个分支、多个 agent。
这时候竞争点就不只是模型能力,而是:
谁能让 Agent 在长流程里不迷路。
谁能让失败变成下一轮改进信号。
谁能让人类随时接管。
谁能让整个过程可观察、可审计、可恢复。
这就是 Loop Engineering 的价值。
它和 Harness Engineering 的关系
我之前写过 Harness Engineering。
如果说 Harness 是 Agent 的安全带、仪表盘和执行外壳,那么 Loop 就是 Agent 的任务推进机制。
Harness 解决的是:
它能不能安全地做事?
Loop 解决的是:
它能不能一轮一轮把事情推进到完成?
两者不是替代关系。
没有 Harness 的 Loop,很危险。
没有 Loop 的 Harness,只是一个安全但不会持续推进的工具壳。
真正的 Coding Agent 需要两者叠在一起:
Harness 管权限、环境、日志、沙箱、回滚。
Loop 管计划、执行、反馈、验证、恢复、退出。
再往下还有 Context Engineering,因为每一轮 loop 都要决定上下文怎么装配。
这几个东西加起来,才是 Agent 工程化。
我已经在项目里这么做了
我后来翻了一下自己本地两个项目,发现其实我已经在按这个方向做了,只是当时不一定把它叫 Loop Engineering。
一个是 boss-skill。
它表面上是一个“从需求到部署”的多 Agent 研发流水线,里面有 PM、Architect、Dev、QA 这些角色。但真正有意思的不是“有 9 个 Agent”,而是它怎么让这些 Agent 不乱跑。
比如它会把一次 feature 的过程落到 .boss/<feature>/ 下面:
events.jsonl 是状态真相源,execution.json 是只读投影,workflow-plan.json 是编译出来的 DAG。阶段状态不是靠某个 Agent 自己说一句“我完成了”,而是按 pending -> running -> completed/failed -> retrying -> running 这种状态机走。
更关键的是,execution.workflow.nextNodeIds 会告诉编排器下一批真正可调度的节点是什么。也就是说,下一个 Agent 不是凭感觉派出去的,而是由当前状态、产物依赖、门禁结果一起算出来的。
这就很 Loop Engineering。
因为 loop 里最怕的不是“没有下一步”,而是“下一步没有依据”。
boss-skill 里还有一个我觉得很典型的设计:子 Agent 返回 DONE 或 DONE_WITH_CONCERNS,不等于事实完成。Wave 边界还要跑自动校验,类型检查、测试、lint、diff 都可能把流水线拦下来。QA 如果认为代码有问题,可以发 REVISION_NEEDED,编排器会记录 RevisionRequested 事件,重派上游 Agent 修订,再让当前 Agent 复验,而且最多 2 轮。
这就是一个很朴素但很重要的事实:
Agent 的声明不能当真相,验证结果才是下一轮的输入。
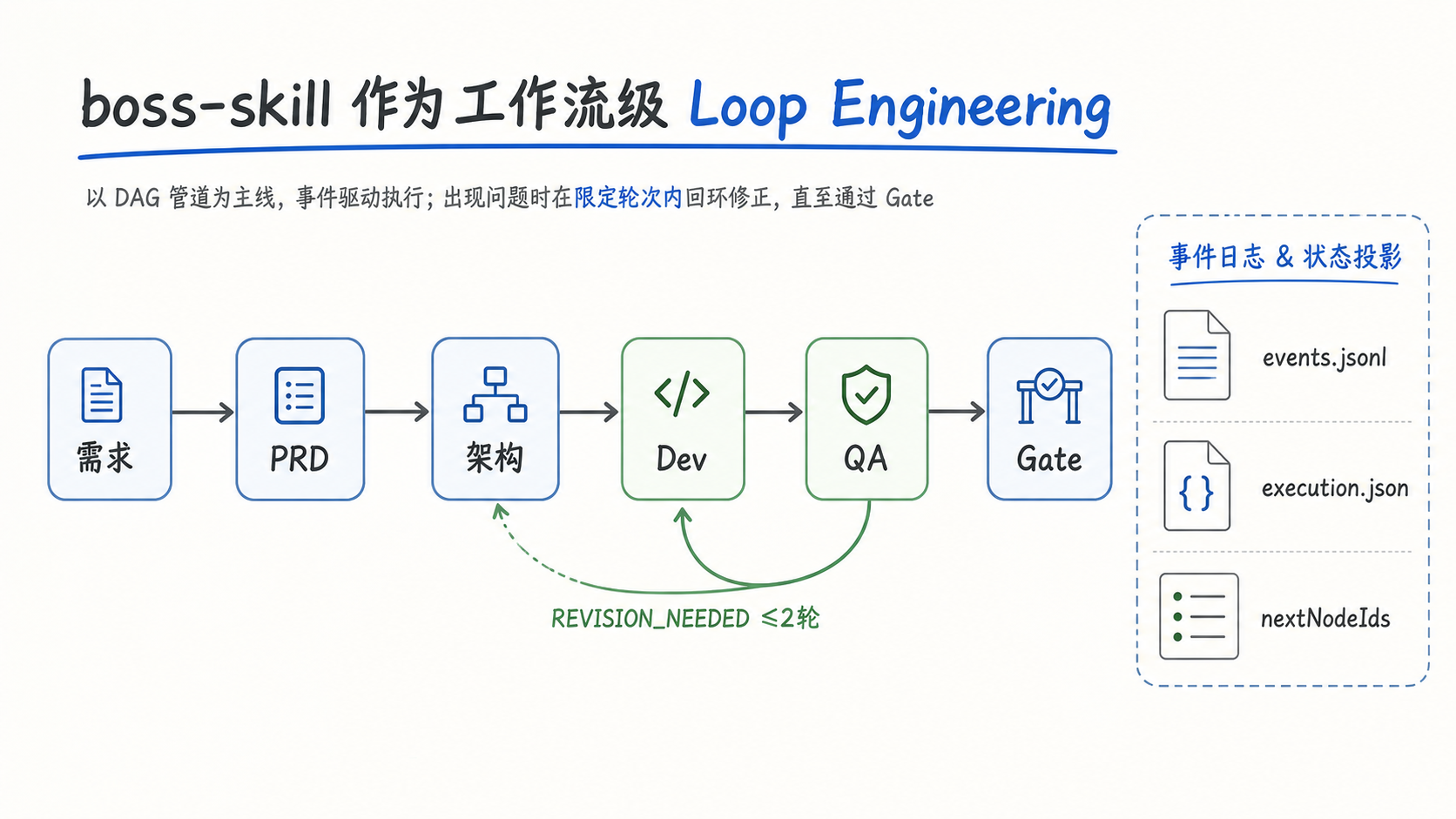
boss-skill 更像工作流层的 loop,把 DAG、事件日志、状态投影、门禁和反馈修订串起来。
另一个是 orca。
它更偏底层运行时。
现在里面的 workflow 已经有 run / list / show / stop / pause / resume / clone / restart-failed / restart-phase 这些控制面。每次运行有 run_id、task_id、session_id,有 state.json、control.json、evidence.json、mailbox.json、task-lists.json、transcripts/ 和 agent-cache.json。
这听起来像一堆文件,但它们解决的是同一个问题:长任务不能只活在上下文窗口里。
一个 Agent 调用会记录 attempt、max_attempts、previous_errors、transcript_path、usage、tool_events。暂停和停止不是靠“你别跑了”这种自然语言,而是写入 control request;恢复时可以按输入 hash 复用之前成功的 Agent 输出;只重启某个 phase 时,也不用把整条链路重新烧一遍。
更底下还有 verifier。它会看 evidence bundle、失败数、transcript 是否存在、有没有违反 read-only mutation policy、required tool call 有没有真的发生。也就是说,“完成”不是模型自己宣布的,而是要能被证据证明。
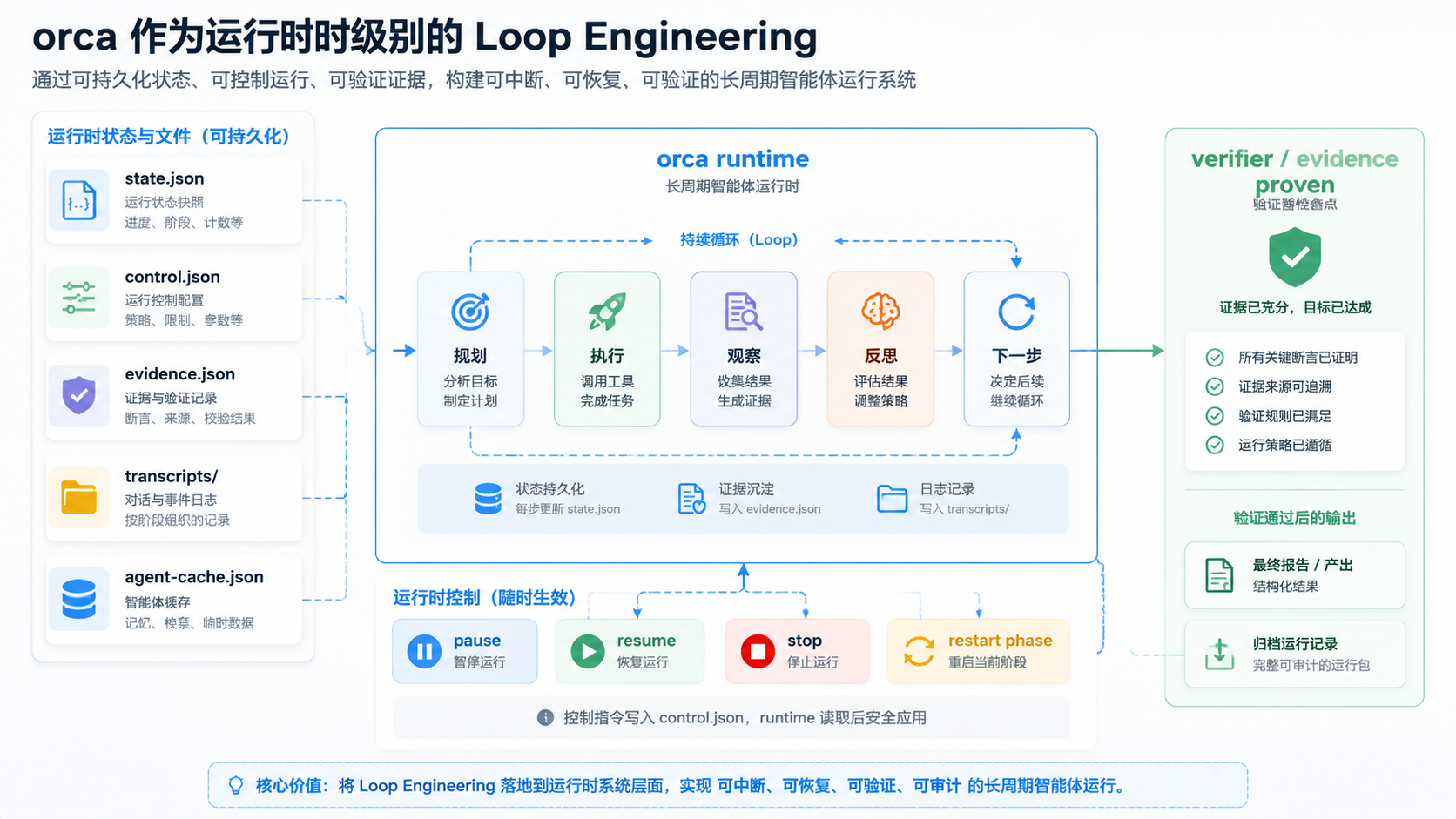
orca 更像运行时层的 loop,让长任务的状态、控制、缓存、证据和 transcript 都能落下来。
所以这两个项目其实正好对应 Loop Engineering 的两层:
boss-skill 做的是工作流层的 loop:需求、产物、DAG、门禁、反馈、重派。
orca 做的是运行时层的 loop:状态持久化、暂停恢复、失败重启、缓存复用、证据验证。
看出来了吧,Loop Engineering 不是在 while true 外面包一层好听的名字。
它真正要工程化的是:一个长期任务在每一轮之后,怎么留下状态,怎么产生下一步,怎么验证自己没有跑偏,怎么在失败后恢复,以及怎么让人能随时接手。
最容易踩的坑
第一个坑,是把 loop 做成无限重试。
测试不过,就继续让模型修。修不过,就再修。再不过,还修。
这种 loop 最后通常会把代码越改越乱。
好的 loop 必须有失败语义:连续失败几次以后,要么换策略,要么缩小范围,要么请求人类介入。
第二个坑,是没有独立验证。
让写代码的模型自己判断“我写好了”,这很危险。
至少要有测试、lint、typecheck、diff review、静态检查,复杂任务还要有另一个模型或规则系统做 reviewer。
第三个坑,是没有状态边界。
长 loop 最怕上下文越来越脏。
每一轮都把所有历史塞回去,成本会上升,注意力会漂移,旧错误还可能被重新激活。
所以 loop 里必须有 state management:哪些是稳定目标,哪些是当前观察,哪些是历史尝试,哪些可以压缩,哪些必须保留原文证据。
第四个坑,是没有停止条件。
很多 Agent 看起来很努力,其实只是不会停。
不会停的自动化,比不会开始的自动化更危险。
Loop Engineering 的本质
我会这样定义:
Loop Engineering,是围绕 Agent 的持续任务执行,设计目标推进、状态更新、反馈验证、失败恢复和退出条件的一整套工程方法。
它不是让 AI “自己一直干”。
而是让 AI 的每一次行动都被放进一个闭环里:
行动前有目标。
行动中有约束。
行动后有观察。
观察后有验证。
验证后决定继续、修正、停止或交还人类。
如果 Prompt Engineering 解决的是“这一句怎么说”,Loop Engineering 解决的就是“这件事怎么一轮一轮做成”。
我现在越来越觉得,未来 Agent 产品真正的差异,不会只在模型,也不会只在工具数量。
而在 loop 的质量。
同样一个模型,有的产品只能生成一段代码。
有的产品能跑完整任务。
有的产品能失败后自己收敛。
有的产品能跑一天多以后,仍然让人看得懂它为什么还在继续。
这中间差的,就是 Loop Engineering。
所以一句话概括:
Loop Engineering 的本质,是把不稳定的智能,放进一个能持续反馈、持续验证、持续收敛的任务闭环里。
不是让它无限跑。
是让它每跑一轮,都更接近交付。
Keep Reading