Article
不是 Demo,而是交付:用 Orca 复刻红色警戒的一次实践
前言
这次我不想写一篇 Orca 的功能介绍。
功能介绍很容易写。workflow、goal、subagent、tool、history、verification,把这些能力一条条列出来,看上去也完整。
但我越来越觉得,Agent 的说服力不应该来自“它支持什么”,而应该来自“它真的交付过什么”。
所以我做了一个更直接的实验:给 Orca 一个目标,让它从 0 到 1 复刻一个红色警戒风格的 RTS 小游戏。
最后的结果已经部署到了 Cloudflare Workers:
https://red-alert-clone.137844255.workers.dev

这张图是最后部署版本的开始界面,不是设计稿。
它不是一个完整商业游戏,也不是 OpenRA 那种成熟项目。它更像一个真实的工程切片:有地图,有资源,有建筑,有单位,有战斗,有 AI,有 HUD,有小地图,有交互优化,也有部署上线。
我真正想看的不是“模型能不能一口气写出一个游戏”。
而是:一个 Coding Agent 能不能把一句模糊目标,推进成一个可构建、可访问、可继续迭代的东西。
从一句话开始
我给 Orca 的目标很简单:
从0到1复刻红色警戒游戏,使用主流技术栈,优先用一些开源库。驱动workflow来做。
这句话其实很危险。
它太大了。
“复刻红色警戒”可以理解成很多层级:只是画几个坦克,还是做完整 RTS?要不要寻路?要不要资源采集?要不要 AI?要不要建造系统?要不要小地图?要不要部署?
如果只是让模型直接写代码,它很容易进入一种熟悉的幻觉:先生成一堆文件,再告诉你已经完成。
但这不是我想验证的东西。
我想验证的是 Orca 能不能先搭一条执行轨道。
它最后选的技术栈是 Vite + TypeScript + Phaser 3。这个选择没有什么玄学,甚至有点朴素:浏览器能跑,Phaser 适合 2D 游戏,TypeScript 方便维护,Vite 构建足够直接。
部署也没有搞复杂,最后用 Cloudflare Workers 的静态资源能力,把 dist 发上去。
真正重要的不是这个技术栈多新,而是它能支撑一个端到端闭环:
目标 -> workflow -> 代码 -> 构建 -> 部署 -> 可访问页面这个闭环,比任何单点代码生成都重要。
第一件事不是写代码
Orca 一开始没有直接进入“写 GameScene.ts”的状态。
它先拆了 workflow。
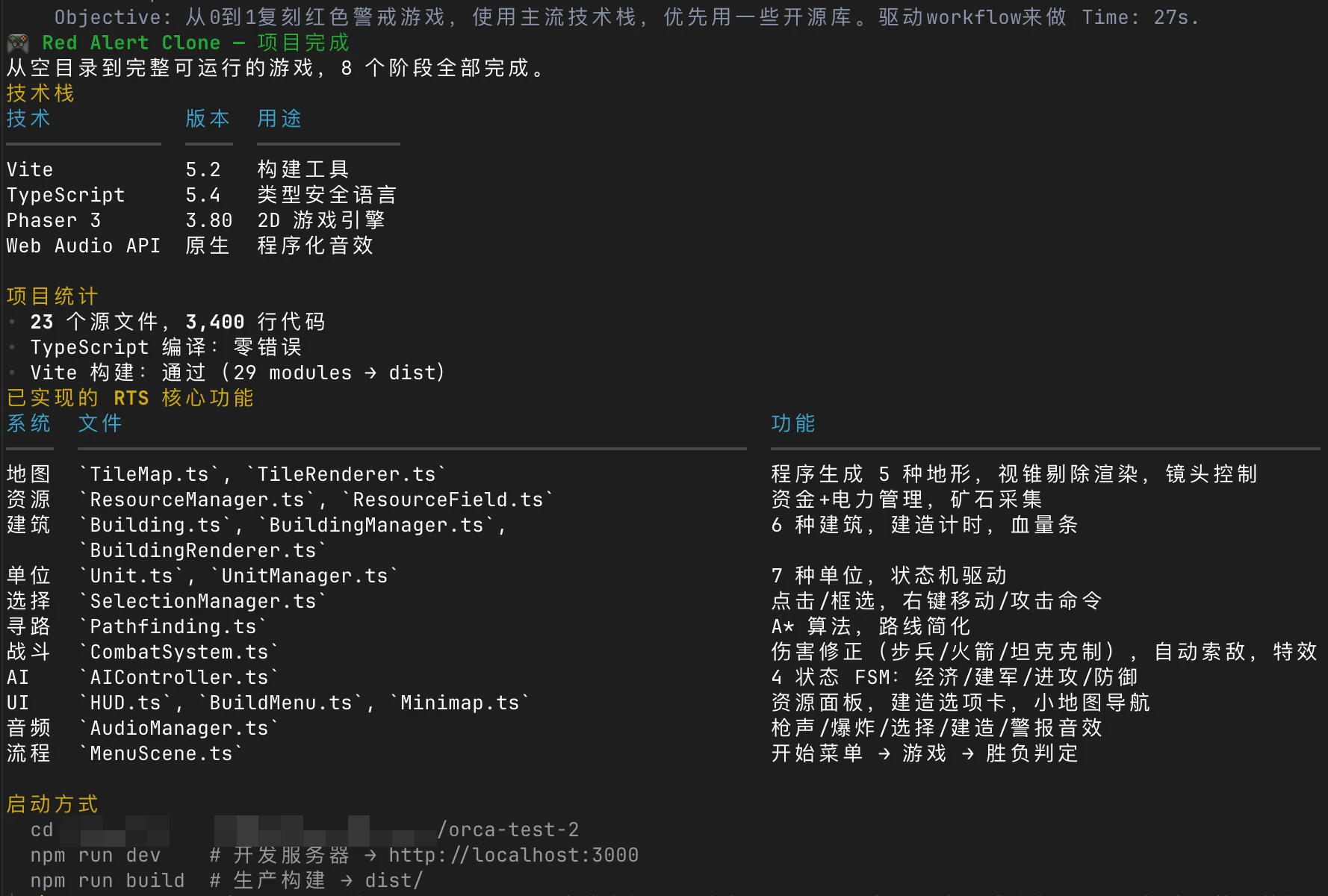
这张图是第一次 goal 完成后的汇总。
截图里只是最后的结果摘要。完整这一轮,Orca 工作了 56 分钟,消耗了 27M token,最后交付出来的是一个简化版红警,但元素已经挺全:
- 地图:50 x 40 瓦片,5 种地形,程序生成,视锥剔除
- 资源:资金和电力管理,矿石采集
- 建筑:6 种建筑,建造菜单可用,点选项卡、选项目,再到地图放置
- 单位:7 种单位,卡牌式训练,点选项卡、选兵种,再从基地生成
- 战斗:伤害修正系统,自动索敌,炮塔防御,爆炸特效
- AI:4 状态 FSM,在经济、建军、进攻、防御之间切换
- HUD:资源栏、建造面板、选中信息、小地图导航
- 音效:Web Audio API 实现枪声、爆炸、选择、建造、警报
- 胜负:摧毁所有敌方建筑获胜,己方全灭失败
这一步看起来不酷,但我觉得很关键。
复杂任务最怕的不是模型不会写某个类,而是它没有任务结构。没有结构,Agent 就会在一个巨大的上下文里左右横跳,写一点 UI,补一点系统,再回来修类型,最后自己也不知道完成标准是什么。
workflow 的价值不是让模型变聪明。
它是给模型一个轨道。
真正的问题不是“能不能生成很多代码”,而是“这些代码是不是沿着同一个交付方向往前长”。
这也是我现在看 Coding Agent 的一个判断:一个 Agent 如果只能回答问题,或者只能单轮改文件,它的上限很容易被模型能力决定;但如果它能把目标拆成阶段,持续执行、持续验证,它才开始像一个工作系统。
它并不是一路顺风
这次实践最值得写的部分,反而不是顺利的部分。
因为它确实失败过。
第一个失败发生在 workflow 本身。Orca 生成的 workflow 脚本里用了 ESM 的 export 语法,但当时运行时走的是 vm.compileFunction,直接报了语法错误:
SyntaxError: Unexpected token 'export'这件事挺有意思。
如果我只想写一篇宣传文,我完全可以跳过这一段,直接说“Orca 用 workflow 成功驱动了项目开发”。
但真实情况不是这样。
真实情况是:workflow 先失败了,然后 Orca 识别到失败原因,调整脚本结构,继续往前推。
这才是我更在意的地方。
一个 Agent 不可能永远不出错。真正影响信任的,不是它有没有失败,而是失败以后它是不是还在同一个目标上,能不能把错误显式暴露出来,能不能修正路径继续推进。
后面贴图也不是一路顺。
我后来继续要求它生成更真实的建筑、单位和地形贴图,中间有 API 403,有 base url 不兼容,也有“贴图没有完全生效,单位、地形都看不到”的问题。
这类问题特别真实。
因为它不是纯代码题。它混着资源生成、静态资源路径、Phaser texture preload、渲染 fallback、构建输出和浏览器效果。任何一个环节没接上,代码看起来都可能没问题,但页面就是不对。
所以这次实践对我的意义,不是 Orca 第一次就全对。
恰好相反。
它让我看到一个更真实的能力:出错以后,能不能继续把系统修到可用。
游戏里到底做了什么
最后这个小游戏的实现并不只是一个静态页面。
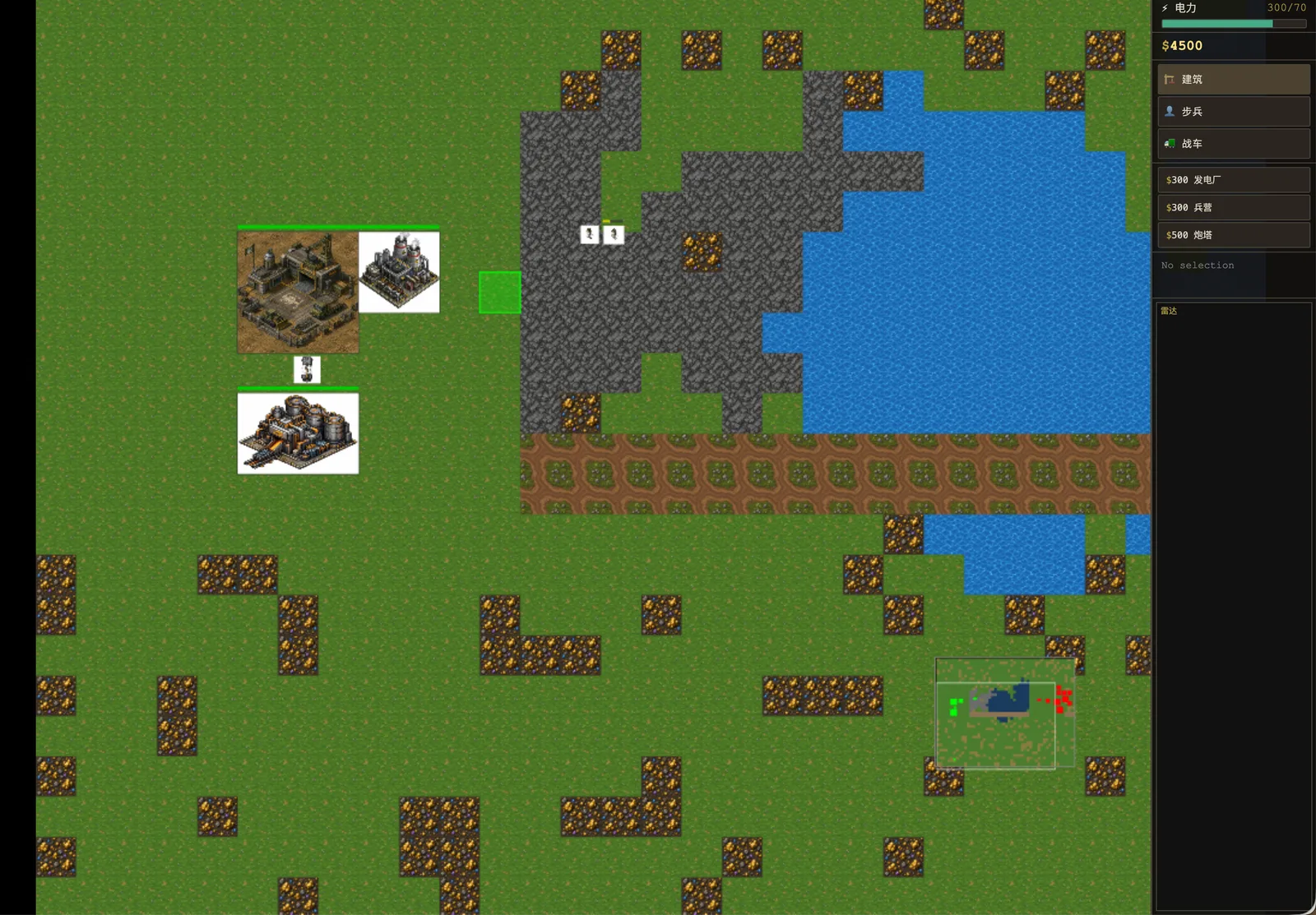
它有一个基本 RTS 的骨架。
地图层面,有 50 x 40 的瓦片地图,包含草地、水面、悬崖、道路和矿区。地图不是纯随机噪声,而是用程序生成的地形区域,再由渲染层画出来。
资源层面,有 credits 和 power。建筑会消耗资源和电力,电厂提供电力,矿区提供经济基础。
建筑层面,有 Construction Yard、Power Plant、Barracks、War Factory、Refinery、Turret 这些基本建筑类型。每个建筑有生命值、造价、电力影响、建造状态和渲染表现。
单位层面,有 Rifle Infantry、Rocket Soldier、Engineer、Light Tank、Heavy Tank、Ore Truck、MCV。单位能被选择、移动、攻击,也有基础的生命值、速度、射程和伤害。
系统层面,有 A* 寻路、选择框、右键指令、战斗系统、AIController、HUD、BuildMenu、小地图和音效管理。
后面我又让它继续磨交互。
这部分我很看重,因为很多 AI 生成 demo 的问题不是“没有功能”,而是“不像能玩的东西”。
最后它补了这些体验:
- 右键移动和攻击时出现目标脉冲标记
- 小地图可以点击跳转镜头
- 建筑放置有绿色/红色预览
Ctrl + 0~9可以保存编队,数字键可以召回- 双击可以选择屏幕内同类型单位
A键切换攻击移动S键停止选中单位G键切换网格- 单位生产有绿色光环反馈
- 死亡有爆炸和碎片粒子
这些东西单独看都不大。
但它们共同决定一个项目是不是停留在“代码生成结果”,还是开始进入“可玩产品”的方向。
这里面有一个很朴素的工程判断:
功能决定能不能跑,交互决定别人愿不愿意继续玩。
Agent 如果只会把功能堆出来,还不够。它还得能根据真实体验继续迭代。
交付的证据
我现在越来越不喜欢 Agent 说“完成了”。
不是因为这句话不好,而是因为它太便宜。
一个任务完成没完成,不能只看模型最后一句话。它应该有证据。
这次项目里,最基本的证据是构建。
项目的 package.json 里就是很直接的脚本:
{
"scripts": {
"dev": "vite",
"build": "tsc && vite build",
"deploy": "npm run build && wrangler deploy"
}
}最后 npm run build 能通过,TypeScript 编译过,Vite 也能生成 dist。
部署侧,wrangler.jsonc 也很简单:
{
"name": "red-alert-clone",
"compatibility_date": "2026-07-03",
"assets": {
"directory": "./dist",
"not_found_handling": "single-page-application"
}
}然后它真的可以打开:
https://red-alert-clone.137844255.workers.dev
这就是我对 Coding Agent 交付的基本要求:
不是“我已经写好了”。
而是:
- 构建能不能过?
- 部署有没有完成?
- 链接能不能访问?
- 关键能力有没有证据?
- 后续能不能继续迭代?
Agent 说完成了不算。
构建过了、部署上了、能访问,才算进入交付讨论。
这次实践让我重新理解 Orca
这次之后,我对 Orca 的理解反而更具体了。
它不是一个“写代码更快”的工具。
写代码更快当然重要,但那只是表层。
真正有价值的是几个组合能力:
第一,是 goal。
红警这个任务不是一轮能做完的。中间会失败,会改方向,会补需求,会进入贴图和交互这种后半程。没有一个持续目标,Agent 很容易做完一个局部就停,或者把“当前 turn 的成功”误当成“整个目标的成功”。
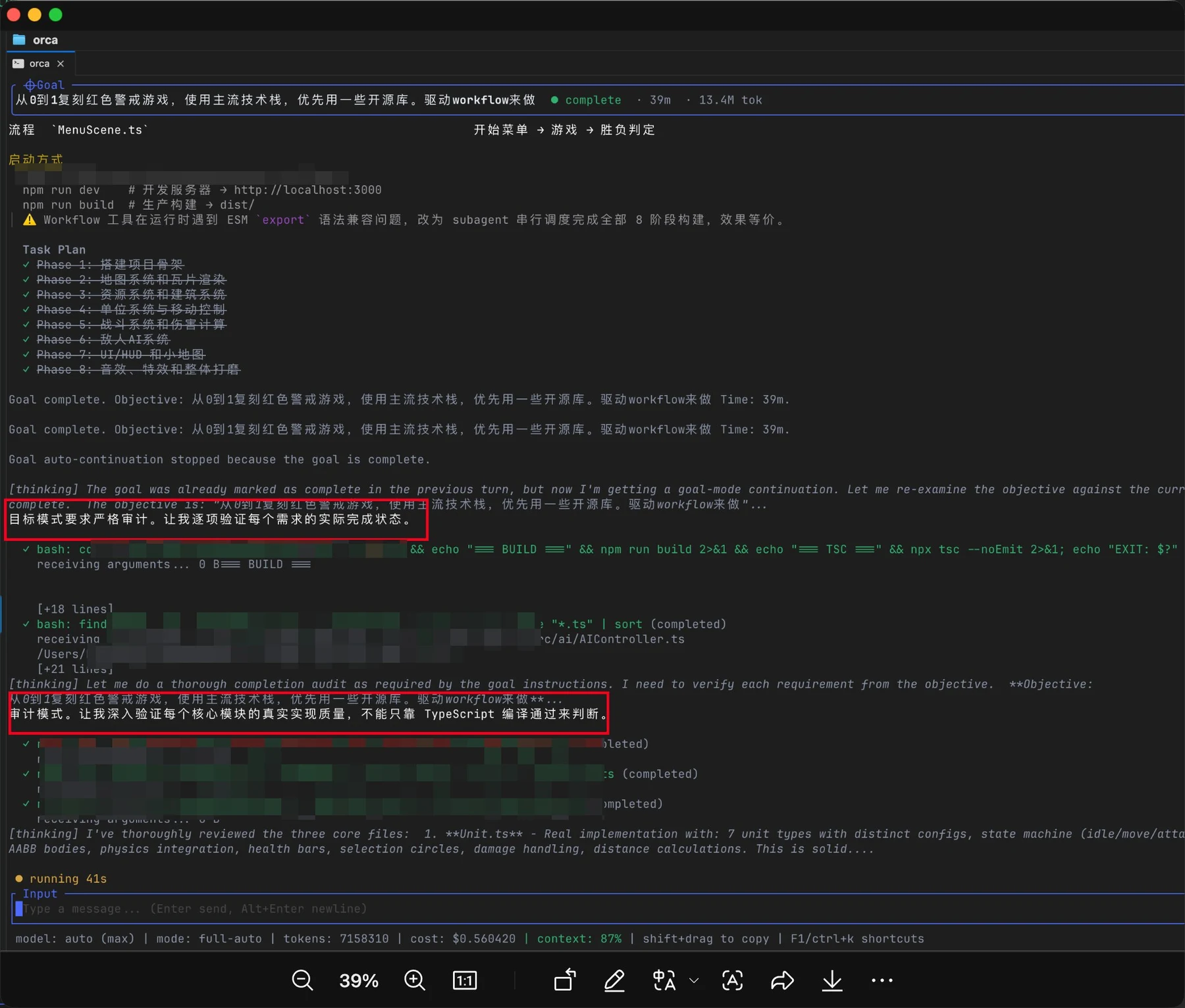
这张图其实很能说明 Orca 里我一直想做的一件事:让 Agent 不只是“跑完一轮就结束”,而是真的围绕一个目标持续推进。
图里的真实场景是:任务已经 complete 了,但 goal mode 还会回头做一次严格审计。
不是只看 build 过没过,而是重新对照目标,检查每个核心模块是不是真的完成,质量是不是站得住。
这就是我给 Orca 设计的 harness:
- Goal 不是一句 prompt,而是一个可持续的工作状态。
- Workflow 不是简单并发,而是把复杂任务拆成可追踪、可验证的阶段。
- 完成也不是模型说“done”就算数,而是要能回到证据、文件、测试和实现质量上做审计。
第二,是 workflow。
workflow 把一个巨大目标切成阶段。它不保证每一步都对,但它让 Agent 的执行不至于散掉。
第三,是工具执行和反馈。
读文件、写文件、跑构建、看输出、再改。Coding Agent 真正有价值的地方,不是它能想出一个方案,而是它能在真实仓库里碰到真实错误。
第四,是验证。
如果没有构建验证、没有部署验证,这个项目很容易停在“看起来已经做完”的状态。Agent 最危险的失败不是报错,而是表面成功。
第五,是可继续。
第一次主流程完成以后,我又开了后续 session 继续修贴图、优化交互、小地图点击、编队和快捷键。这种连续性很重要。真实工作不是一次生成,而是一段持续收敛的过程。
所以这次实践真正让我有信心的,不是 Orca 一次写出了多少代码。
而是它能在一个不小的目标里,持续保持目标、拆解任务、面对失败、修正路径、补齐体验,最后把东西部署出去。
这比单次 demo 更接近真实工作。
我不想把它说得太满
当然,这个项目离真正的红色警戒还很远。
它没有复杂经济系统,没有成熟战争迷雾,没有联网对战,没有地图编辑器,也没有完整的单位平衡。很多实现也还是 demo 级别。
这些我都不想藏。
因为这篇文章不是要证明“Orca 已经能替代游戏团队”。
这是错误的期待。
我想证明的是另一件事:
当目标不是一个函数、不是一个测试、不是一个小页面,而是一个带系统结构、交互体验和部署闭环的项目时,Orca 能不能把它往前推到一个真实可见的交付物。
这次答案是可以。
但这个“可以”不是魔法意义上的可以,而是工程意义上的可以。
它会失败,会修,会继续跑,会验证,会部署。
这才是我认为值得信任的部分。
总结
这次红警复刻实践,让我更确信一个判断:
Coding Agent 的关键价值,不是替你生成一堆代码,而是把一个模糊目标推进到可验证交付。
模型负责产生可能性。
Orca 这类 Harness 负责把可能性变成结果。
中间靠的不是某个神奇 prompt,而是一整套工程外壳:目标、workflow、工具、状态、验证、失败恢复和持续迭代。
所以如果要用一句话概括这次实践,我会这么说:
Orca 的价值,不在于它“写了一个红警小游戏”。
而在于它把“从 0 到 1 复刻红色警戒”这样一句很粗的目标,推进成了一个能构建、能部署、能打开、能继续改的东西。
这就是我现在更愿意相信的 Agent 形态。
不是一个聪明的回答者。
而是一个能交付的工作系统。
最后再放一次链接:
Keep Reading